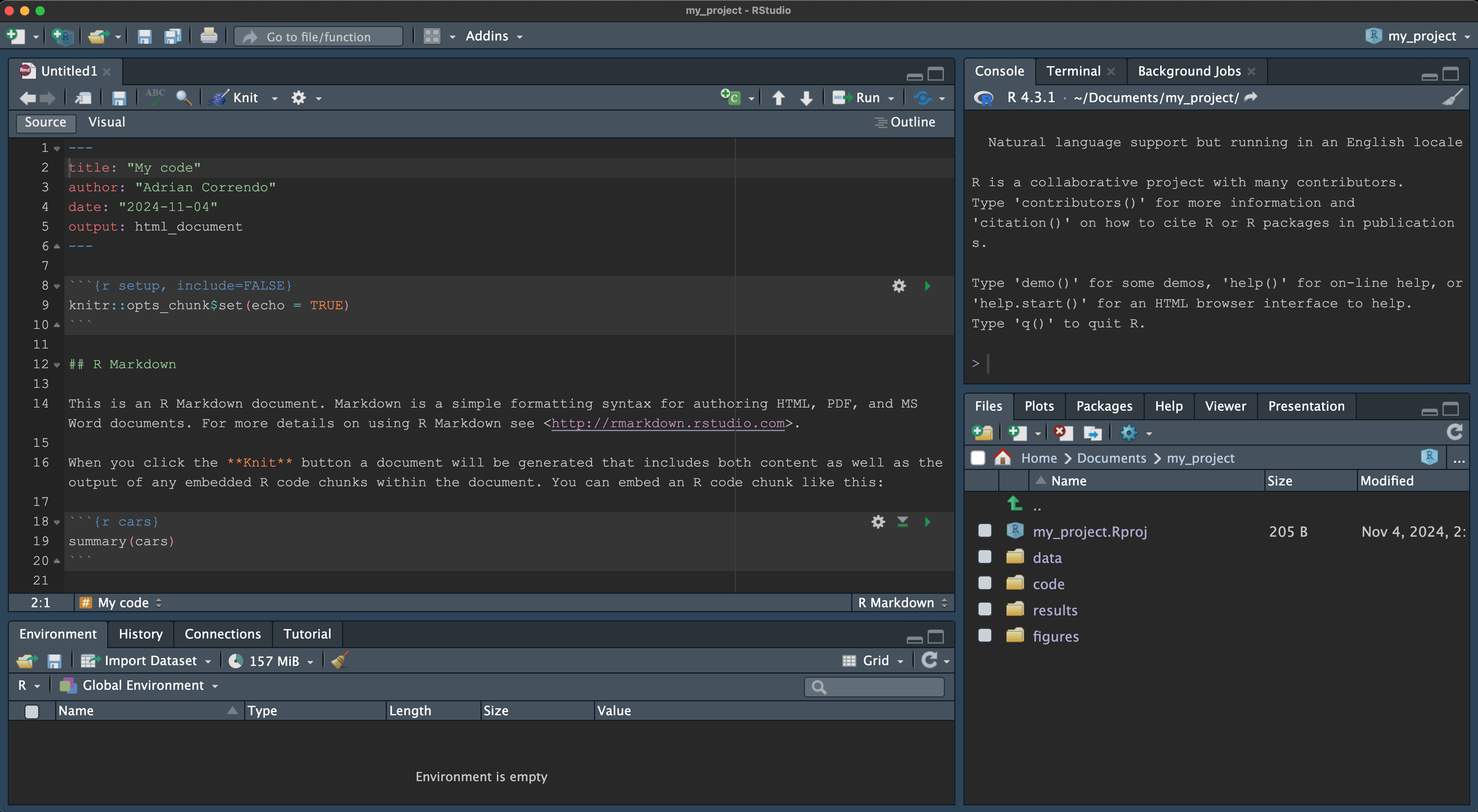
[1] 20[1] 5The essentials of R
2025-11-26
![]()
![]()

![]()
![]()
![]()
![]()




![]()
![]()
A package is a collection of R functions, data sets, and compiled code in a well-defined format.

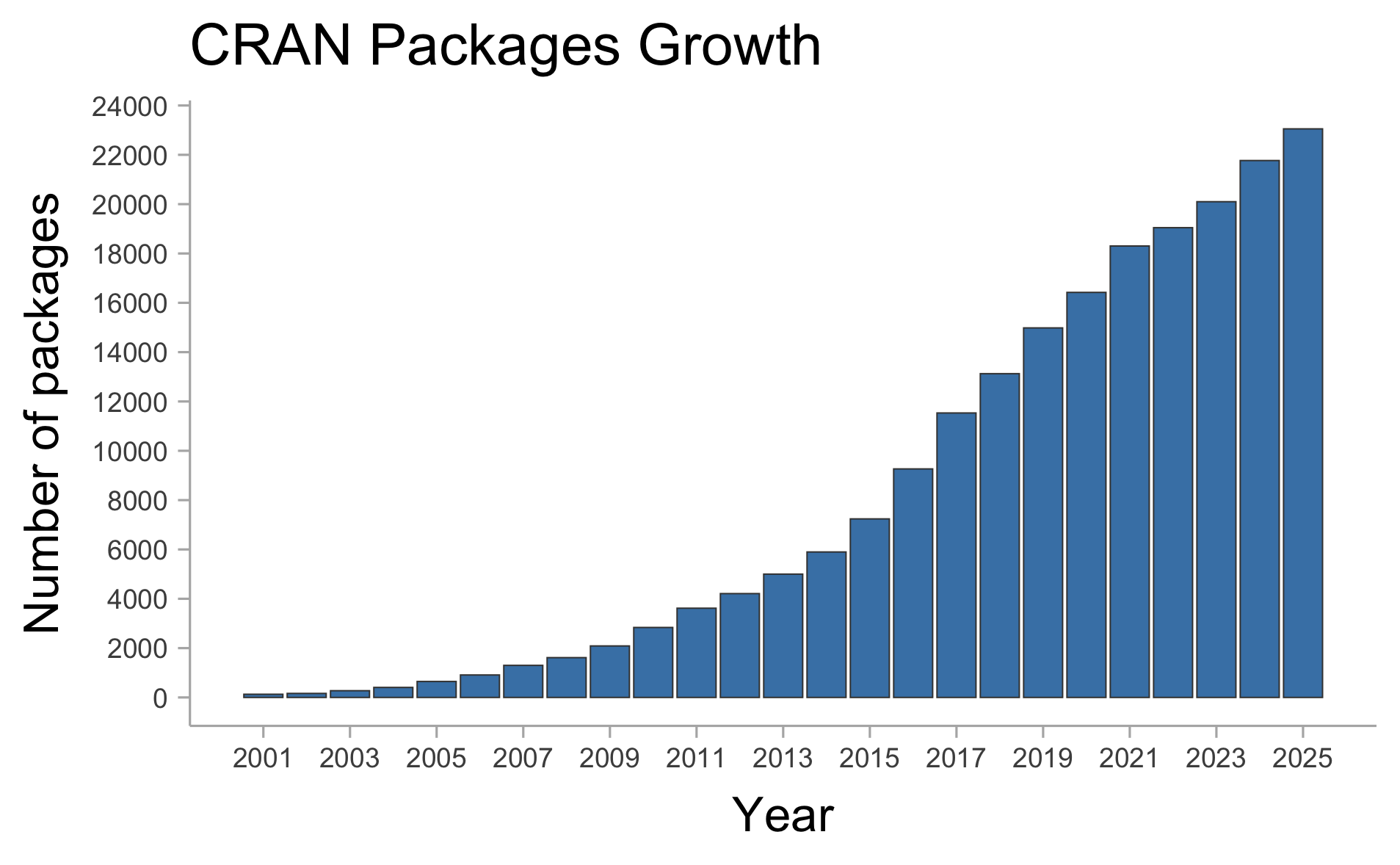
There are currently 23,052 of packages (on CRAN only).
The “tidy data” framework changed the way we code and work in R for data science. Tidy datasets are easy to manipulate, model and visualize, and have a specific structure:
Each variable is a column,
Each observation is a row, and
Each value have its own cell.
Tidy-data structure. Following three rules makes a dataset tidy: variables are in columns, observations are in rows, and values are in cells (Wickham, 2017).



acorrend@uoguelph.ca Adrian A. Correndo
Assistant Professor
Sustainable Cropping Systems
Department of Plant Agriculture
University of Guelph
Rm 226, Crop Science Bldg | Department of Plant Agriculture Ontario Agricultural College | University of Guelph | 50 Stone Rd E, Guelph, ON-N1G 2W1, Canada.
 |
||
 |