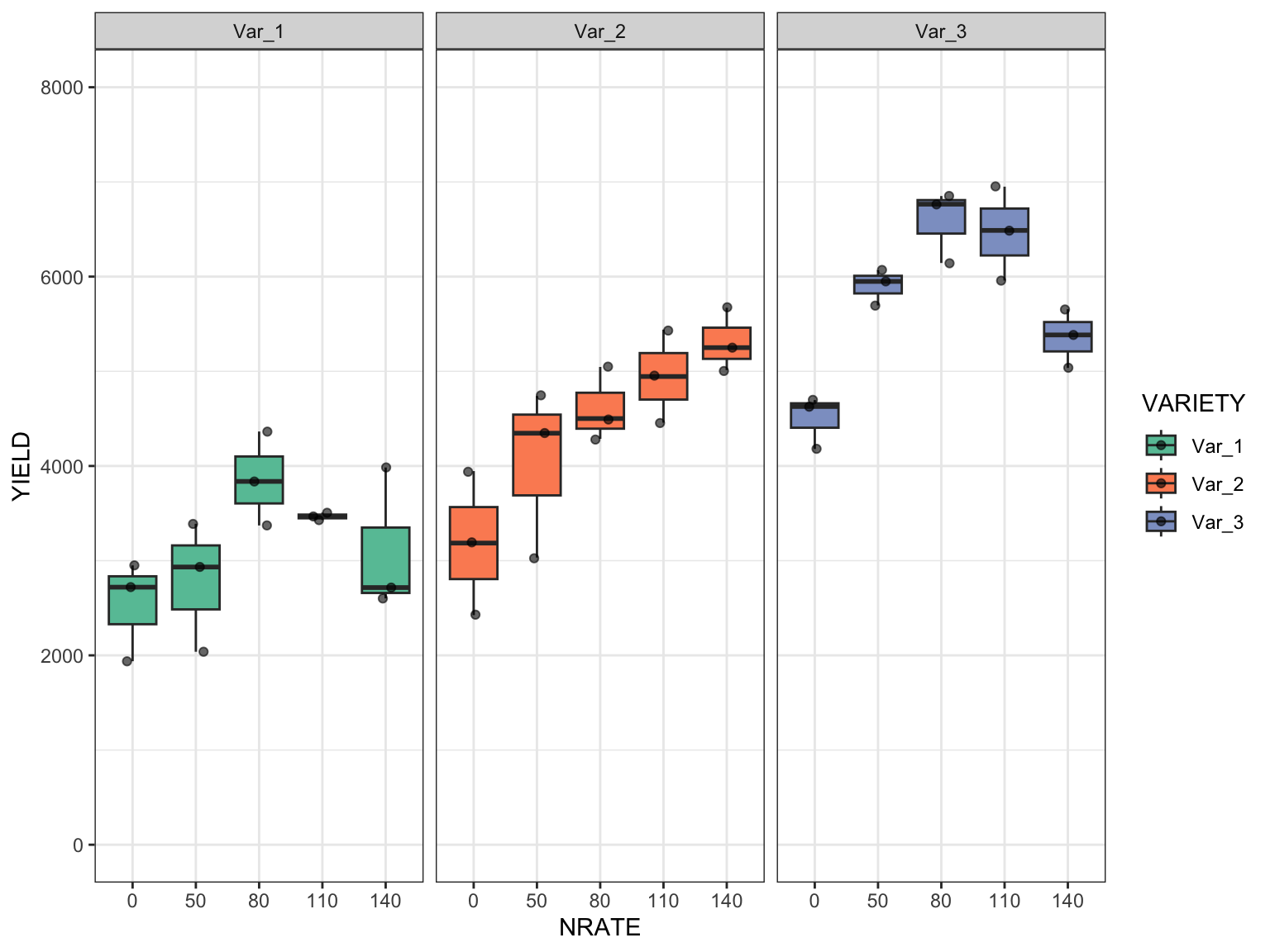
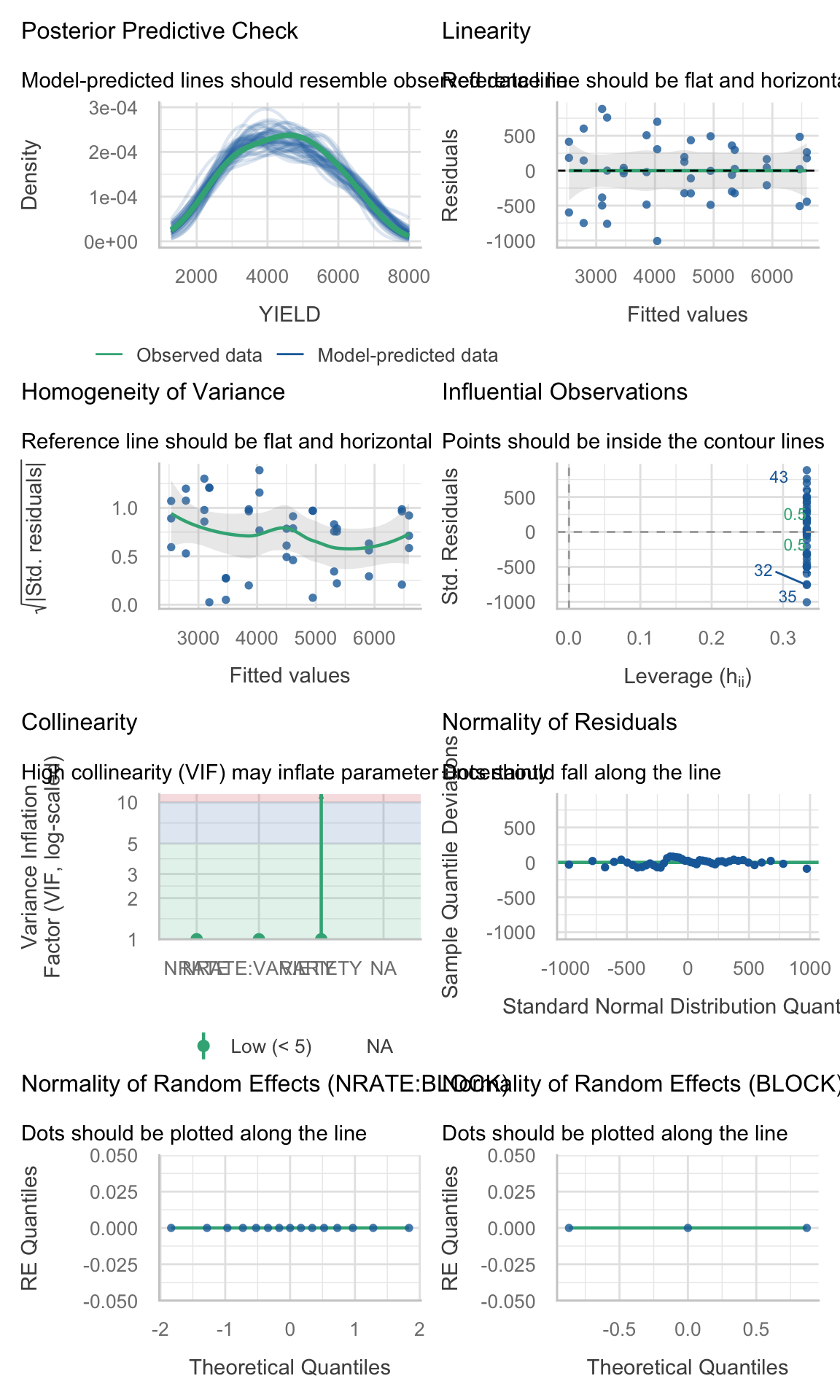
Rows: 160
Columns: 9
$ row <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2…
$ col <int> 1, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 2, 20, 3, 4, 5, 6, 7,…
$ yield <int> 64, 69, 67, 66, 71, 64, 64, 75, 70, 66, 67, 68, 65, 68, 71, 62, …
$ inoc <fct> Uninoc, Uninoc, Uninoc, Inoc, Inoc, Uninoc, Uninoc, Inoc, Inoc, …
$ trt <fct> 5, 7, 1, 1, 9, 9, 10, 10, 2, 2, 6, 5, 6, 4, 4, 3, 3, 8, 8, 7, 6,…
$ gen <fct> Marquis, Marquis, Marquis, Marquis, Marquis, Marquis, Marquis, M…
$ dry <fct> Dry, Dry, Dry, Dry, Dry, Dry, Wet, Wet, Wet, Wet, Wet, Dry, Wet,…
$ dust <fct> DuBay, Check, Ceresan, Ceresan, CaCO3, CaCO3, CaCO3, CaCO3, Cere…
$ block <fct> B1, B1, B1, B1, B1, B1, B1, B1, B1, B1, B1, B1, B1, B1, B1, B1, …