This article provides some basics about Bayesian statistics and a comparison with the conventional frequentist perspective about probabilities and statistical inference.
Important
Neither Frequentist nor Bayesian approaches are universally superior. Each has strengths, limitations, and situations where it is more useful.
1 Why should we care?
In agricultural research, we rarely work with perfect data. We often deal with small sample sizes, noisy field conditions, site-year variation, and previous knowledge coming from earlier trials, expert opinion, or long-term experiments.
Because of that, statistics is not just about computing a p-value. It is about learning from data while being honest about uncertainty.
Bayesian statistics offers one way to do that. It is not magic, and it is not automatically better than conventional methods. But it gives us a useful framework to combine previous knowledge with observed data and express uncertainty in a direct way.
Today, we will compare the Frequentist and Bayesian perspectives, and discuss what each approach can do well (and not so well) for applied agricultural science.
2 Frequentism vs Bayesianism
What are your thoughts?
Let’s open the floor for discussion!
2.1 Main differences
The key difference lies in where uncertainty is placed.
2.1.1 Frequentist perspective
In Frequentist statistics, parameters are treated as fixed but unknown, and randomness comes from the data-generating process.
It is called frequentist because probability is defined in terms of long-run frequencies under repeated sampling.
🎲 Example: To estimate the probability of rolling a 6, a Frequentist would say: “If we rolled the die many times under the same conditions, the proportion of 6s would approach its true probability.”
So the logic of inference is based on hypothetical repetition of the same experiment.
2.1.2 Bayesian perspective
In Bayesian statistics, unknown quantities are treated as uncertain, and that uncertainty is represented with probability distributions.
This does not mean truth does not exist. It means that, before observing enough data, we describe our uncertainty about the unknown using probability.
For example, if the probability of rolling a 6 is unknown, we may call it \(\theta\) and assign a prior distribution to \(\theta\). After observing data, we update that prior into a posterior distribution.
Bayesian inference is built around the idea of updating beliefs with data:
Prior: what we assumed or believed before seeing the data
Likelihood: how compatible different parameter values are with the observed data
Evidence: a scaling constant that makes the posterior a proper probability distribution
Posterior: our updated belief after observing the data
4.1 Video: Bayes’ Rule
5 The priors
Priors formalize previous information or assumptions as probability distributions.
They can be based on:
the nature of the variable (discrete or continuous),
previous experiments,
expert knowledge,
or deliberately weak assumptions when prior information is limited.
Tip
In practice, analysts often use weakly informative priors when they want the data to dominate the analysis while still ruling out unreasonable parameter values.
A prior is not necessarily subjective guesswork. In many applied problems, it can represent previous field trials, historical datasets, or realistic agronomic constraints.
At the same time, priors should not be treated carelessly. With limited data, they can influence results strongly.
6 A simple agronomic example
Suppose we want to estimate the economically optimum nitrogen rate (EONR) for corn.
A Frequentist approach might fit a response curve and produce a point estimate and confidence interval for EONR.
A Bayesian approach could do the same, but it can also:
incorporate previous site-years as prior information,
express uncertainty in EONR directly through a posterior distribution,
and naturally extend to hierarchical models across years, sites, hybrids, or landscape positions.
So instead of only reporting a single estimate, we could describe our updated uncertainty about the optimum nitrogen rate as:
\[
P(\text{EONR} \mid \text{data})
\]
That is, our inference about EONR is conditional on both the observed data and the assumptions used in the model.
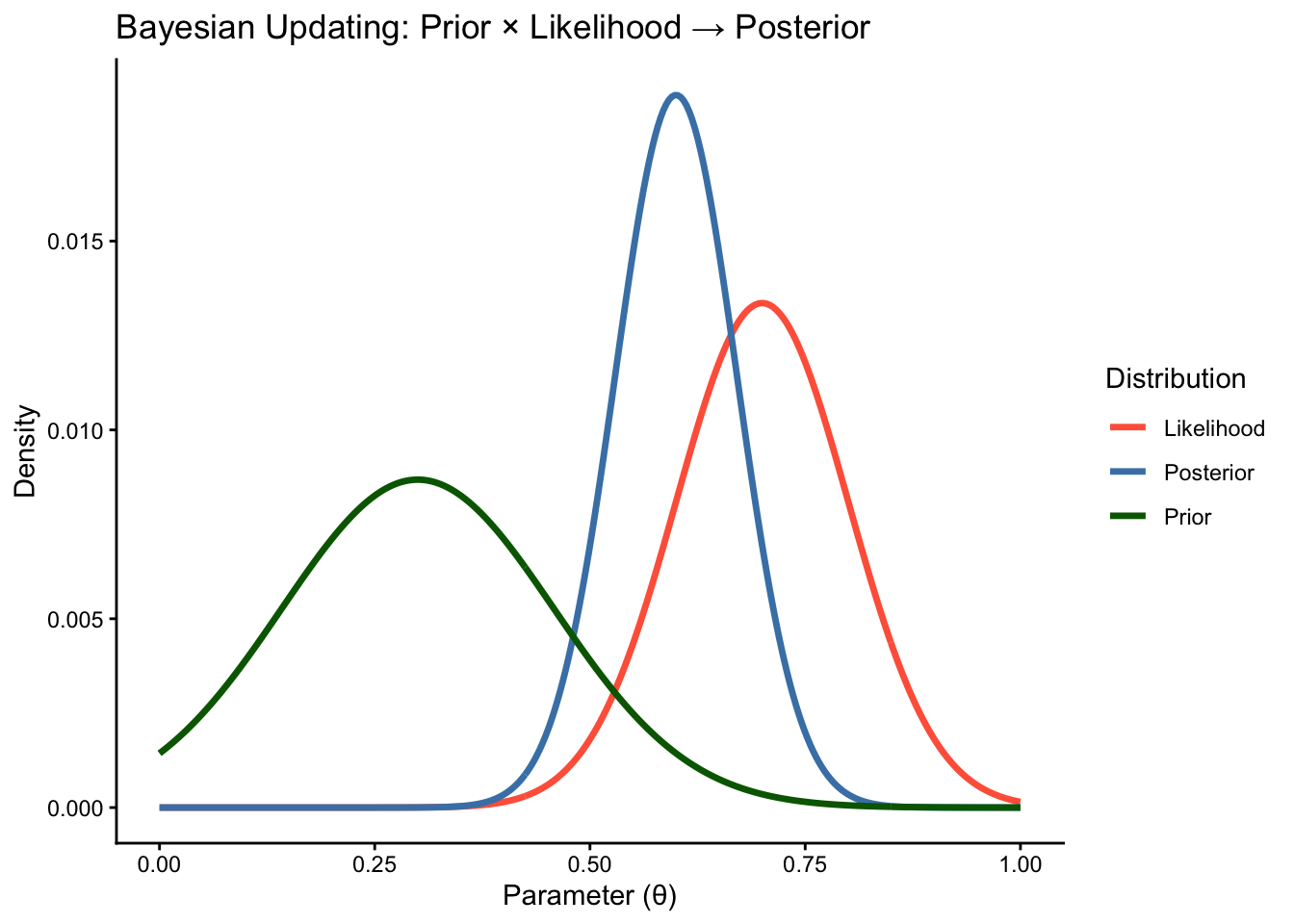
7 Visualization of Bayesian updating
The following figure is a conceptual sketch of Bayesian updating. It is meant to illustrate the idea of combining prior information with observed data through the likelihood to obtain a posterior distribution.
A common source of confusion in statistics is the interpretation of intervals.
Confidence interval (Frequentist): If we repeated the experiment many times under the same conditions, 95% of the intervals produced by that method would contain the true parameter value.
The parameter is treated as fixed. The interval procedure has a long-run success rate of 95%.
Credible interval (Bayesian): Given the observed data, the model, and the prior assumptions, there is a 95% probability that the parameter lies within the interval.
This interpretation is often more intuitive, but it is conditional on the model and prior assumptions.
9 Bayes factor and model comparison
When comparing two competing models, Bayesians may use the Bayes factor, which measures how much more strongly the observed data support one model over another:
prior odds represent what we believed before seeing the data,
Bayes factor represents what the data contributed,
posterior odds represent our updated support for one model relative to another.
Note
For an introductory course, Bayes factors are helpful mainly as a model-comparison concept. They are not required to understand the basic prior-likelihood-posterior workflow.
10 The good, the bad, and the ugly
10.1 Frequentist approaches
10.1.1 The good
Widely taught and widely used
Many standard tools work very well for common agronomic experiments
Straightforward workflows for familiar analyses such as ANOVA, regression, and mixed models
10.1.2 The bad
P-values are often over-interpreted
Confidence intervals are commonly explained incorrectly
Results are sometimes reduced to a simple significant/non-significant decision
10.1.3 The ugly
Mechanical threshold thinking can replace scientific judgment
Statistical significance can be confused with agronomic relevance
Selective reporting and p-hacking can distort conclusions
10.2 Bayesian approaches
10.2.1 The good
Probability statements about parameters are often more intuitive
Prior information can be incorporated formally
Very flexible for hierarchical models, small datasets, and complex uncertainty structures
10.2.2 The bad
Requires more modeling decisions
Priors can affect results, especially when data are limited
Computation can be slower and model checking can be more demanding
10.2.3 The ugly
Poorly chosen priors plus weak data can be misleading
Complex Bayesian models can create a false sense of rigor
It is easy to trust software output without checking convergence, model fit, and sensitivity to priors
11 Final thoughts
Bayesian statistics is not a replacement for good scientific thinking, and it is not automatically superior to frequentist methods.
Its main value is that it gives us a coherent way to combine prior information, observed data, and uncertainty into a single inferential framework.
In many simple problems, Frequentist and Bayesian approaches may lead to similar answers. The real advantage of Bayesian methods often becomes clearer when:
data are limited,
multilevel structure matters,
previous knowledge is relevant,
or decision-making under uncertainty is central.
For applied agricultural science, the best method is usually the one that matches the research question, the structure of the data, and the kind of uncertainty we need to communicate.
Lacasa et al., 2020 (Sci. Rep.) Bayesian approach for maize yield response to plant density from both agronomic and economic viewpoints in North America
Palmero et al., 2024 (Plant Methods) A Bayesian approach for estimating the uncertainty on the contribution of nitrogen fixation and calculation of nutrient balances in grain legumes